Data Time vs Natural Time
What is Data Time Scheduled?
Data time scheduling is based on the time of the received data. For example, if the app is scheduled to run every 10 minutes and 20 minutes of new data is received, 2 events will be created. One invoke may contain 1 or more events, each having different time range. This is to minimize the overhead that would be caused by having a separate invoke for every event when the well is catching up to real time.
Since this scheduling type is not based on the clock, invokes might occur in irregular intervals. If the app fails to execute the events (e.g. throws an error or times out), events will be resent for 48 hours in order to prevent data loss since the apps typically rely on the time ranges specified in the events.
This type is suitable for applications that perform calculations based on the event time ranges. Good examples are summary apps with fixed intervals.
Events
Event Properties Property Description company_id Company ID start_time Left bound of the time range, covered by this event. Use inclusively. start_time Right bound of the time range, covered by this event. Use inclusively.
Event Properties
Here's an example of the event generation when a lagging asset is catching up to real time and the app is scheduled to run every 10 minutes:
Scenario
Real time: 2022/04/03 13:00:00
Current asset time: 2022/04/03 12:10:00 (50 minutes behind)
Scenario
1st invoke
System receives 20 minutes worth of data when catching up (from 2022/04/03 12:10:00 to 2022/04/03 12:30:00)
Events:
[
{
asset_id: 1234,
company_id: 1,
start_time: 1649005800, (2022/04/03 12:10:00)
end_time: 1649006400 (2022/04/03 12:20:00)
},
{
asset_id: 1234,
company_id: 1,
start_time: 1649006400, (2022/04/03 12:20:00)
end_time: 1649007000 (2022/04/03 12:30:00)
}
]
1st invoke
2nd invoke
System receives 20 minutes worth of data when catching up (from 2022/04/03 12:30:00 to 2022/04/03 12:50:00)
Events:
[
{
asset_id: 1234,
company_id: 1,
start_time: 1649007000, (2022/04/03 12:30:00)
end_time: 1649007600 (2022/04/03 12:40:00)
},
{
asset_id: 1234,
company_id: 1,
start_time: 1649007600, (2022/04/03 12:40:00)
end_time: 1649008200 (2022/04/03 12:50:00)
}
]
2nd invoke
3rd invoke
System receives 10 minutes worth of data and catched up to real time (from 2022/04/03 12:50:00 to 2022/04/03 13:00:00)
Events:
[
{
asset_id: 1234,
company_id: 1,
start_time: 1649008200, (2022/04/03 12:50:00)
end_time: 1649008800 (2022/04/03 13:00:00)
}
]
3rd invoke
4th invoke
System is now receiving data in real time and once 2022/04/03 13:10:00 is reached, new event will be generated
Events:
[
{
asset_id: 1234,
company_id: 1,
start_time: 1649008800, (2022/04/03 13:00:00)
end_time: 1649009400 (2022/04/03 13:10:00)
}
]
4th invoke
Example
Full example of an app that calculates mean weight on bit 10 minute summaries:
import statistics
from corva import Api, Cache, Logger, ScheduledDataTimeEvent, scheduled
@scheduled
def lambda_handler(event: ScheduledDataTimeEvent, api: Api, cache: Cache):
# You have to fetch the realtime drilling data for the asset based on start and end time of the event.
# start_time and end_time are inclusive so the query is structured accordingly to avoid processing duplicate data
# We are only querying for weight_on_bit field since that is the only field we need.
records = api.get_dataset(
provider='corva',
dataset='wits',
query={
'asset_id': event.asset_id,
'timestamp': {
'$gte': event.start_time,
'$lte': event.end_time,
}
},
sort={'timestamp': 1},
limit=600,
fields='data.weight_on_bit'
)
# If we did not find any records, we can stop the execution early
if not records:
Logger.info('Data not found')
return None
# Getting last processed timestamp from cache
last_exported_timestamp = int(cache.load(key='last_processed_timestamp') or 0)
# Making sure we are not processing duplicate data
if event.end_time <= last_exported_timestamp:
Logger.info(f'Already processed data until {last_exported_timestamp}')
return None
# Computing mean weight on bit from the list of realtime wits records
mean_weight_on_bit = statistics.mean(record.get('data', {}).get('weight_on_bit', 0) for record in records)
Logger.info(f'Calculated mean WOB: {mean_weight_on_bit}')
# Building the output
output = {
'timestamp': event.end_time,
'asset_id': event.asset_id,
'company_id': event.company_id,
'provider': 'my-company',
'collection': 'my-dataset',
'data': {
'mean_weight_on_bit': mean_weight_on_bit,
'start_time': event.start_time,
'end_time': event.end_time
},
'version': 1
}
# If request fails, function will be re-invoked. so no exception handling
# This is to prevent data loss in case of the POST to API fails
api.post(
f'api/v1/data/my-company/my-dataset/', data=[output],
).raise_for_status()
# Storing the processed timestamp to cache for the next invoke
cache.store(key='last_processed_timestamp', value=event.end_time)
return
Full example
What is Natural Time Scheduled?
Natural time scheduling is based on the clock time. For example, if the app is scheduled to run every 10 minutes, it will get invoked once every 10 minutes, even if there is no new data available. App continues to get invoked until the well stream is stopped.
Unlike with data time scheduling, natural time apps events will not be resent if the app execution fails. This is because the apps don't rely on the time ranges inside the events.
This type is suitable for applications that do not directly depend on the time ranges that are passed in data time scheduled events.
NOTE: App timeout should be set to be less than the scheduled interval in order to prevent overlapping invocations.
Events
Event Properties Property Description company_id Company ID schedule_start Scheduled event trigger time. interval how often the scheduled event gets triggered.
Event properties
Scenario
Current time: 2022/04/03 13:00:00
Well stream was started at: 2022/04/03 13:00:00
App is scheduled to run every: 5 minutes
Scenario
1st invoke
Current time is 2022/04/03 13:00:00
Event:
{
asset_id: 1234,
company_id: 1,
schedule_start: 1649008800, (2022/04/03 13:00:00)
interval: 300 (5 minutes)
}
1st invoke
2nd invoke
Current time is 2022/04/03 13:10:00
Event:
{
asset_id: 1234,
company_id: 1,
schedule_start: 1649009100, (2022/04/03 13:05:00)
interval: 300 (5 minutes)
}
2nd invoke
3rd invoke
Current time is 2022/04/03 13:10:00
Event:
{
asset_id: 1234,
company_id: 1,
schedule_start: 1649009400, (2022/04/03 13:10:00)
interval: 300 (5 minutes)
}
3rd invoke
Example
Full example of a very simple app that tracks the total number of WITS records:
from corva import Api, Cache, Logger, ScheduledNaturalTimeEvent, scheduled
@scheduled
def lambda_handler(event: ScheduledNaturalTimeEvent, api: Api, cache: Cache):
# Fetch the latest record from the WITS dataset
latest_record = api.get_dataset(
provider='corva',
dataset='wits',
query={'asset_id': event.asset_id},
sort={'timestamp': -1},
limit=1,
fields='timestamp,data.weight_on_bit'
)
# If we did not find any records, we can stop the execution early
if not latest_record:
Logger.info('Data not found')
return None
latest_record = latest_record[0]
# Get latest processed timestamp from the cache
last_processed_timestamp = int(cache.load(key='last_processed_timestamp') or 0)
# Return early if we have already processed this data
if latest_record['timestamp'] <= last_processed_timestamp:
Logger.info('No new data')
return None
# Get new records
new_records = api.get_dataset(
provider='corva',
dataset='wits',
query={
'asset_id': event.asset_id,
'timestamp': {
'$gt': last_processed_timestamp,
}
},
sort={'timestamp': 1},
limit=1000,
fields='timestamp'
)
# Get the record we want to update
records = api.get_dataset(
provider='my-company',
dataset='my-dataset',
query={
'asset_id': event.asset_id,
},
sort={'timestamp': -1},
limit=1,
fields='timestamp'
)
if not records:
# Create a new record if we have don't have it yet
output = {
'timestamp': event.end_time,
'asset_id': event.asset_id,
'company_id': event.company_id,
'provider': 'my-company',
'collection': 'my-dataset',
'data': {
'total_count': len(new_records)
},
'version': 1
}
api.post('/api/v1/data/my-company/my-dataset/', data=output)
else:
# Update the existing record
record = records[0]
output = {
'data': {
'total_count': record['data']['total_count'] + len(new_records)
}
}
api.patch(f'/api/v1/data/my-company/my-dataset/{record["id"]}/', data=output)
# Storing the processed timestamp to cache for the next invoke
cache.store(key='last_processed_timestamp', value=new_records[-1]['timestamp])
return
Full example
Visuals of Data Use Cases
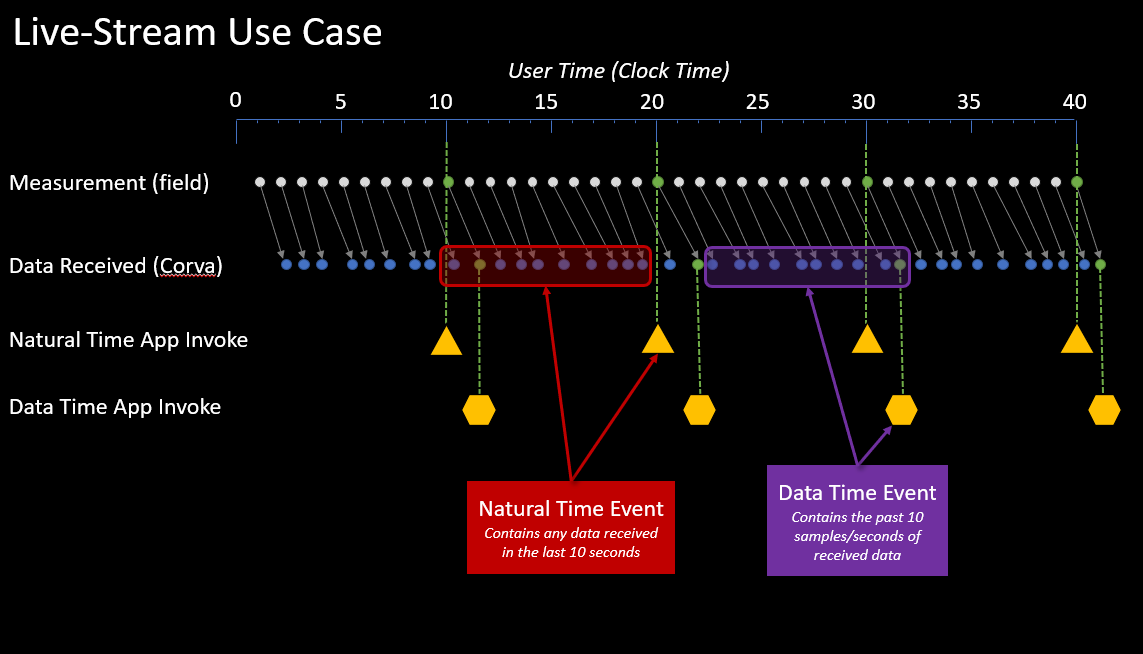
Live-Stream Use Case: In the live stream use case below, there is no delay of data coming in from the field to Corva's cloud. The Natural time and Data time intervals are set to 10 seconds. The Measurement (field) row represents the data events that are being captured on the drilling rig or a completion frac site in real time. The Data Received (Corva) row represents the data events that are being received by a Back End Scheduled app in Corva.
The Natural time invokes will receive the available events at the 10 second mark (clock time). The Data time invokes will receive the data every 10 seconds that the was created in the field. Therefore, you may receive a data time event at 11 seconds clock time due to transmission time from field to Corva's cloud.
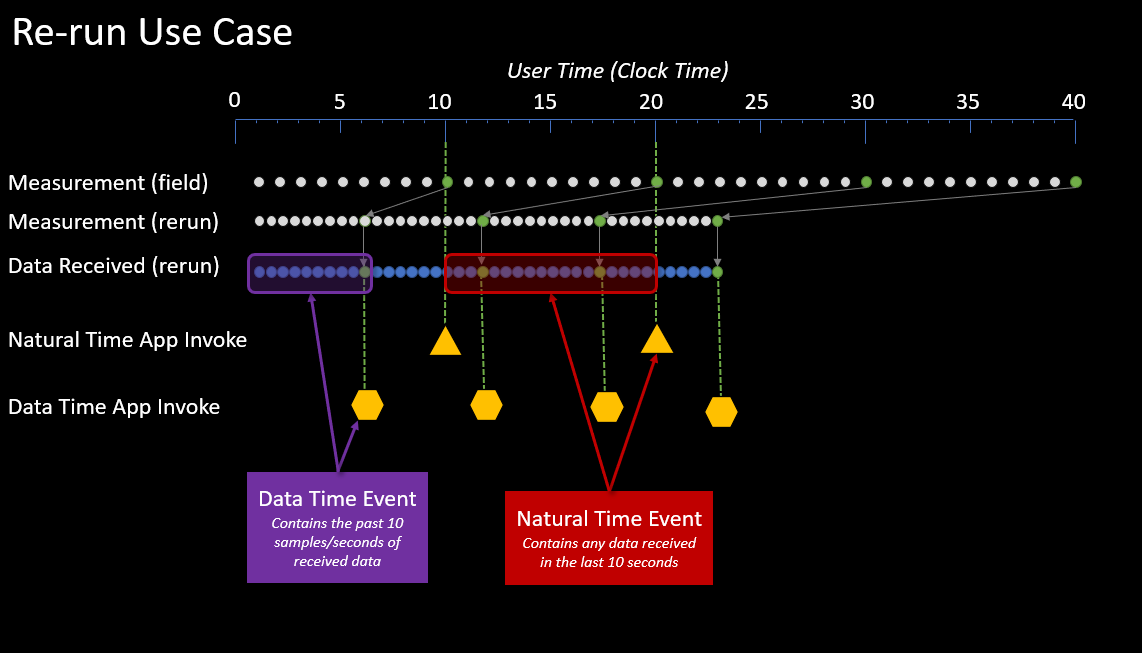
Re-run Use Case: In the re-run use case below, the data is being received from Corva's cloud storage. Re-run data events arrive in a much faster rate than real time data that is arriving from the field.
The Natural time and Data time intervals are set to 10 seconds. The Measurement (field) row represents the data events that are being captured on the drilling rig or a completion frac site in real time. The Measurement (re-run) row represents that data events that are being captured from the historical data in Corva. The Data Received (re-run) row represents the data events that are being received by a Back End Scheduled app in Corva.
The Natural time invokes will receive the available events within the 10 second clock interval. In this example, you may receive 20 events in a 10 second natural clock time interval. The Data time set to 10 second intervals will invoke every time it gets 10 events, therefore, the back end data time app may invoke twice or more within a 10 second clock interval.
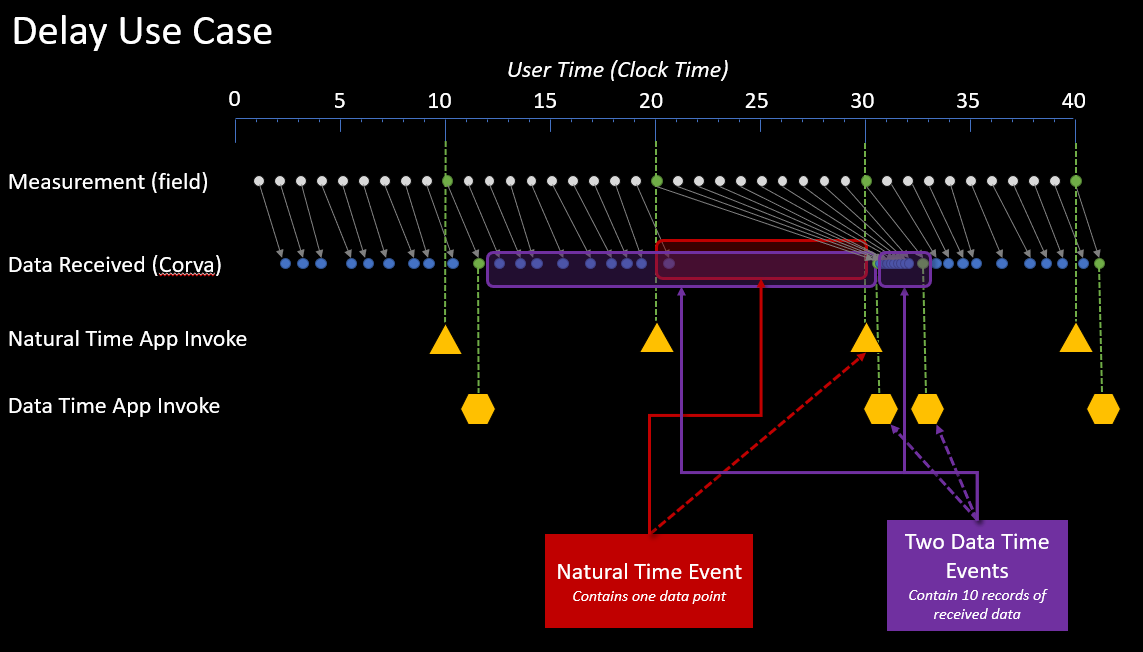
Delay Use Case: In the delay use case below, there is a delay of the data coming in from the field to Corva's cloud. The Natural time and Data time intervals are set to 10 seconds. The Measurement (field) row represents the data events that are being captured on the drilling rig or a completion frac site in real time. The Data Received (Corva) row represents the data events that are being received by a Back End Scheduled app in Corva.
The Natural time invokes will receive the available events within the 10 second clock interval. In this example, you may receive only 8 events in a 10 second natural clock time interval. The Data time set to 10 second intervals will invoke every thime it gets 10 events , therefore, the back end data time app may invoke once in a 20 second clock interval due to the delay of data from the field.